How endpoints and pools become unhealthy
When we talk about dynamic load balancing, that means your load balancer only directs requests to endpoints that can handle the traffic.
But how does your load balancer know which endpoints can handle the traffic? We determine that through a system of monitors, health monitors, and pools.
Dynamic load balancing happens through a combination of pools, monitors, and health checks.
flowchart RL
accTitle: Load balancing monitor flow
accDescr: Monitors issue health monitor requests, which validate the current status of servers within each pool.
Monitor -- Health Monitor ----> Endpoint2
Endpoint2 -- Response ----> Monitor
subgraph Pool
Endpoint1((Endpoint 1))
Endpoint2((Endpoint 2))
end
Health checks are requests issued by a monitor at regular interval and — depending on the monitor settings — return a pass or fail value to make sure an endpoint is still able to receive traffic.
Each health monitor request is trying to answer two questions:
- Is the endpoint offline?: Does the endpoint respond to the health monitor request at all? If so, does it respond quickly enough (as specified in the monitor's Timeout field)?
- Is the endpoint working as expected?: Does the endpoint respond with the expected HTTP response codes? Does it include specific information in the response body?
If the answer to either of these questions is "No", then the endpoint fails the health monitor request.
For each option selected in a pool's Health Monitor Regions, Cloudflare sends health monitor requests from three separate data centers in that region.
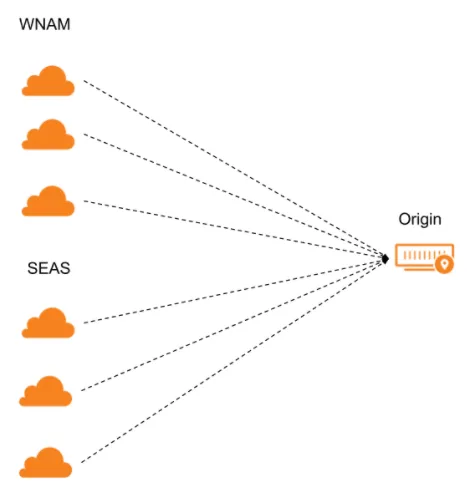
If the majority of data centers for that region pass the health monitor requests, that region is considered healthy. If the majority of regions is healthy, then the endpoint itself will be considered healthy.
Load balancing analytics and logs will only show global health changes.
For greater accuracy and consistency when changing endpoint health status, you can also set the consecutive_up and consecutive_down parameters via the Create Monitor API endpoint. To change from healthy to unhealthy, an endpoint will have to be marked healthy a consecutive number of times (specified by consecutive_down). The same applies — from unhealthy to healthy — for consecutive_up.
When an individual endpoint becomes unhealthy, that may affect the health status of any associated pools (visible in the dashboard):
- Healthy: All endpoints are healthy.
- Critical: The pool has fallen below the number of available endpoints specified in its Health Threshold and will not receive traffic from your load balancer (unless other pools are also unhealthy and this pool is marked as the Fallback Pool).
- Health unknown: There are either no monitors attached to pool endpoints or the monitors have not yet determined endpoint health.
- No health: Reserved for your load balancer's Fallback Pool.
When a pool reaches Critical health, your load balancer will begin diverting traffic according to its Traffic steering policy:
-
Off:
- If the active pool becomes unhealthy, traffic goes to the next pool in order.
- If an inactive pool becomes unhealthy, traffic continues to go to the active pool (but would skip over the unhealthy pool in the failover order).
-
All other methods: Traffic is distributed across all remaining pools according to the traffic steering policy.
This pool is meant to be the pool of last resort, meaning that its health is not taken into account when directing traffic.
Fallback pools are important because traffic still might be coming to your load balancer even when all the pools are unreachable (disabled or unhealthy). Your load balancer needs somewhere to route this traffic, so it will send it to the fallback pool.
When one or more pools become unhealthy, your load balancer might also show a different status in the dashboard:
- Healthy: All pools are healthy.
- Degraded: At least one pool is unhealthy, but traffic is not yet going to the Fallback Pool.
- Critical: All pools are unhealthy and traffic is going to the Fallback Pool.
If a load balancer reaches Critical health and the pool serving as your fallback pool is also disabled:
- If Cloudflare proxies your hostname, you will see a 530 HTTP/1016 Origin DNS failure.
- If Cloudflare does not proxy your hostname, you will see the SOA record.